Weka adalah sebuah perangkat lunak yang memiliki banyak algoritma machine learning untuk keperluan data mining. Weka juga memiliki banyak tools untuk pengolahan data, mulai dari pre-processing, classification, regression, clustering, association rules, dan visualization. Weka adalah perangkat lunak open source berbasis Java dan kita dapat menggunakannya secara langsung atau melalui program Java kita. Weka juga bisa diimplementasikan ke program python. Untuk penjelasan Weka lebih lengkap, kamu bisa membuka halaman dokumentasinya di sini.
Pertama kali saya mengenal Weka ketika mengikuti mata kuliah Information Retrieval, pada pertemuan tentang Clustering. Clustering adalah proses mengelompokkan sekumpulan objek ke kelas-kelas dengan objek yang mirip (Cluster). Clustering adalah salah satu bentuk unsupervised learning. Banyak sekali algoritma untuk clustering, namun secara umum terbagi dua yaitu flat algorithms dan hierarchical algorithms. Pada kuliah tersebut, saya mempelajari tentang algoritma K-means yang merupakan flat algorithms, mulai dari teori K-means hingga implementasinya menggunakan Weka. Pada tulisan ini saya akan berbagi tentang penggunaan Weka untuk aplikasi Simple K-means. Diharapkan teman-teman telah sedikit membaca tentang K-means.
Oh ya, Weka juga dapat diimplementasikan untuk big data!
Instalasi Weka
Kamu bisa mendownload program instalasinya dari sini : http://www.cs.waikato.ac.nz/ml/weka/downloading.html. Sebelum menginstall, cek terlebih dahulu apakah kamu sudah menginstall JRE (Java Runtime Environment). Kamu bisa mengeceknya di folder ini : C:\Program Files\Java. Jika JRE sudah terinstall, kamu cukup mendowload file weka-3-6-11.exe. Jika belum menginstall JRE, kamu harus mendownload file weka-3-6-11jre.exe. Sesuaikan juga file yang didownload dengan tipe sistem operasi kita, apakah 32-bit atau 64-bit.
Setelah berhasil mendownload filenya, jalankan proses instalasi. Ikuti petunjuk instalasi, mudah kok. Setelah selesai, segera buka Weka 🙂

Mulai Menggunakan Weka
Oke. Sebelum mulai menggunakan Weka, kita harus mempersiapkan data yang mau diolah terlebih dahulu. Kamu bisa download file data.csv untuk langsung digunakan. File data.csv berisi data berikut :
| Doc | T1 | T2 | T3 | T4 | T5 |
| 1 | 0 | 3 | 2 | 0 | 0 |
| 2 | 2 | 1 | 0 | 0 | 4 |
| 3 | 0 | 2 | 4 | 0 | 0 |
| 4 | 3 | 0 | 0 | 4 | 0 |
| 5 | 0 | 4 | 3 | 0 | 0 |
| 6 | 4 | 0 | 0 | 0 | 6 |
Terdapat 6 dokumen, yaitu Doc1, Doc2, …, Doc6, dimana setiap dokumen memiliki 5 kata kunci (T1, T2, …, T5). Doc1 hanya memiliki kata kunci T2 dan T3, Doc2 hanya memiliki kata kunci T1, T2, dan T5, begitu seterusnya.
Selanjutnya, buka Weka, dan klik Explorer.

Kemudian klik Open file… dan buka file data.csv tadi. Berikut hasilnya :
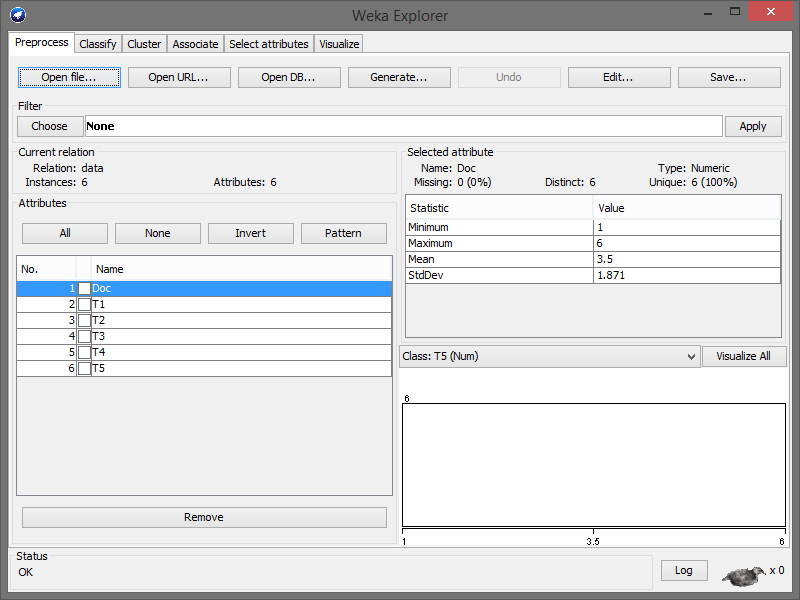
Next step, kita akan langsung mencoba melakukan clustering Simple K-means. Klik tab Cluster, lalu klik tombol Choose, lalu pilih SimpleKMeans, dan klik Start. Tarraaa, ini hasilnya :

Kita telah melakukan Simple K-means dengan numCluster = 2. Kita dapat mengubah numCluster (jumlah cluster) sesuai keinginan kita. Juga kita dapat mengubah parameter algoritma K-means yang lain seperti fungsi untuk distance.
Caranya pertama klik text box di sebelah tombol Choose, kemudian akan muncul windows baru. Ubah numCluster menjadi 3.


Kita juga dapat menvisualisasikan hasil Simple K-means dengan cara klik kanan pada Result list lalu pilih Visualize cluster assignments.


Sekian tutorial singkat tentang penggunaan Weka. Kamu bisa mengeksplorasi lebih jauh sendiri sekarang. Seperti yang saya tulis di awal, Weka memiliki banyak algoritma lain untuk data mining dan fungsi-fungsi Weka dapat diimplemntasikan di program kita.
Semoga bermanfaat 😀

Thanks bro
wah, dikomen oleh kakak blogger. sipp
SEP MANTAP, MAKASIY ILMUNYA”’
terima ksih infonya. saya mau nanya, klo data yg dipake adalah data training DARPA/KDD gmna cara prosesnya.. dan data tersebut akan dicluster menjadi 2 cluster. bagaimna caranya?
terima kasih infonya kak